Convolutional Neural Networks (CNN) has become so popular due to its state of the art results in many computer vision tasks such as Image Recognition, Image Classification, Semantic Segmentation.
For a beginner in Deep Learning, using CNNs for the first time is generally an intimidating experience. Even though it is easier to understand the layers of CNNs such as Convolution, Pooling, Non Linear Activations, Fully Connected layers, Deconvolution when treated individually, its quite difficult to make sense of effect of these operations on each layer’s output size, shape as the networks gets deeper
Figure 1.1 below shows the sample CNN architecture. We can see how the network is stacked up with Convolution, Pooling, Deconvolution layers. At the top of each layers, you can observe the shape of the output mentioned. How did we get those numbers?. This is dependent on the parameters choosen in that layer. That’s what we want to understand.
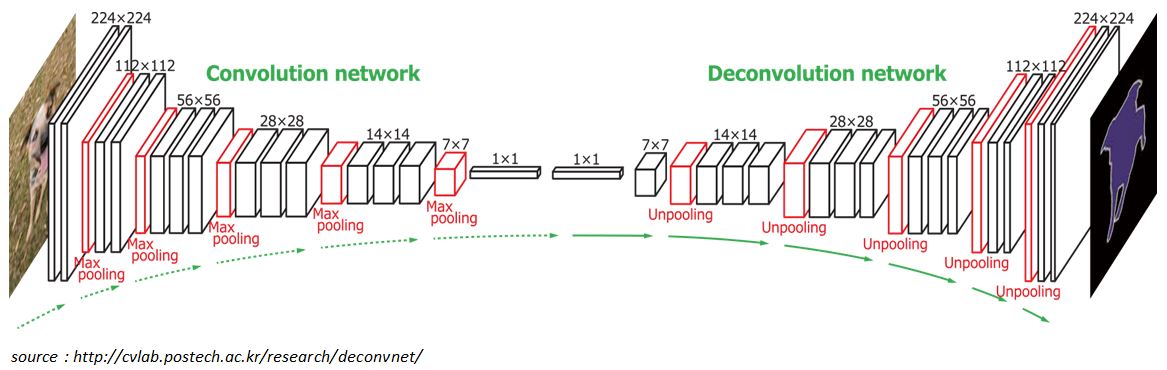
Figure 1.1: CNN architecture
I experienced that good understanding of computational mechanism of convolution, pooling and deconvolution layers and their dependency on parameters such as kernel size, strides, padding together builds a solid ground in understanding CNNs better
The main objectives for rest of the post:
The main building blocks of CNN are Discrete Convolution and Pooling.
If you take MNIST digit recognition as an example, the 2-D input is flattened to a 1-D vector of size and fed as an input to the typical fully connected neural network as shown in Figure 1.2
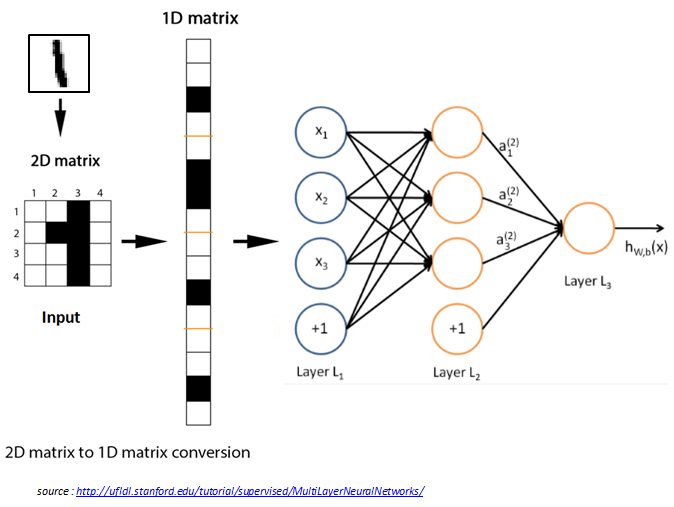
Figure 1.2: Multi-layer perceptron
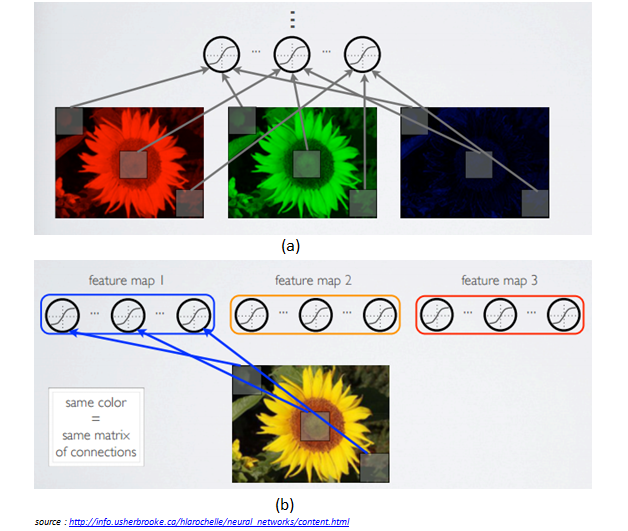
Figure 1.3: (a) Local connectivity (b) Shared weights
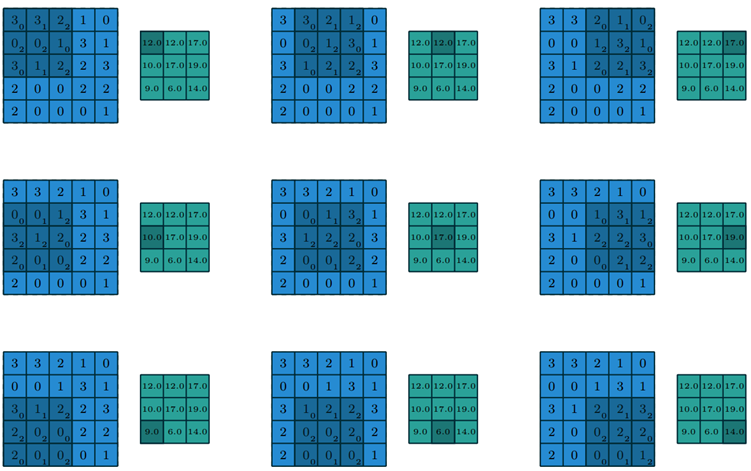
Figure 1.4: Computing the output values of a discrete convolution
The following properties affect the output size \(o_j\) of a convolution layer along the axis \(j\)
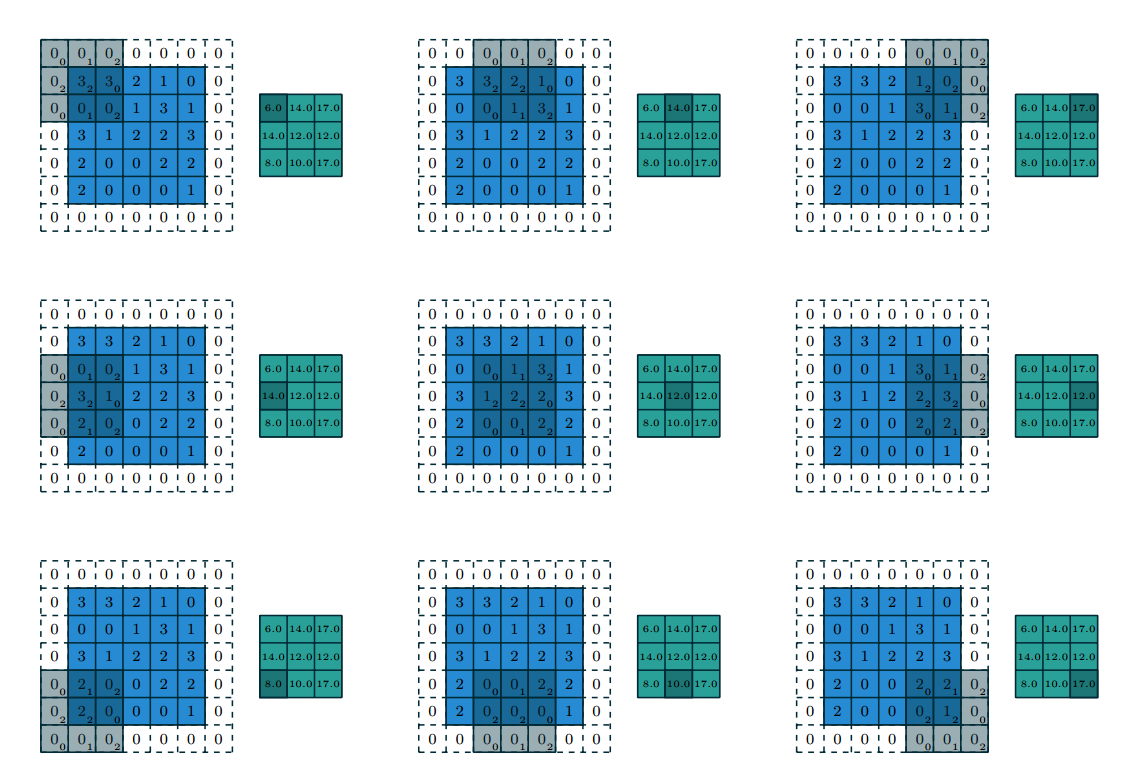
Figure 1.5: Computing the output values of a discrete convolution for \(N=2\) \(i_1 = i_2 = 5\), \(k_1 = k_2 = 3\) , \(s_1 = s_2 = 2\), \(p_1 = p_2 = 1\)
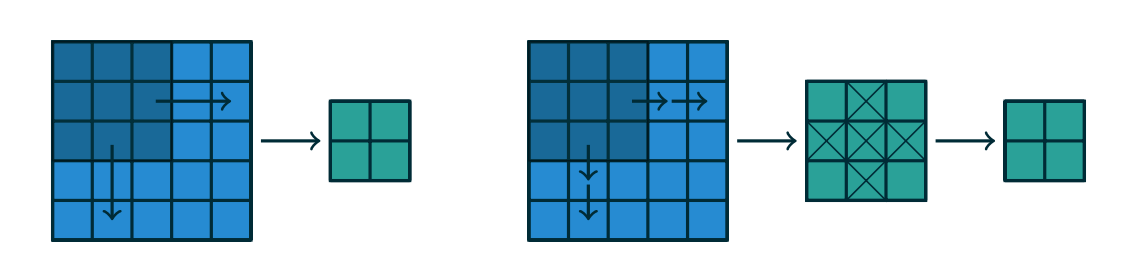
Figure 1.6: An alternative way of viewing strides. Instead of translating the \(3*3\) kernel by increments of \(s=2\) (left), the kernel is translated by increments of \(1\) and only odd numbered output elements are retained
The analysis of relationship between convolutional layer properties is eased by the fact that they don’t interact across axes, i.e., the choice of kernel size, stride and zero padding along the axis \(j\) only affects the output size along the axis \(j\)
The following simplified settings are used to analyse the convolution layer properties
The simplest case to analyse is when the kernel just slides across every position of the input (i.e., \(s = 1\) and \(p = 0\))
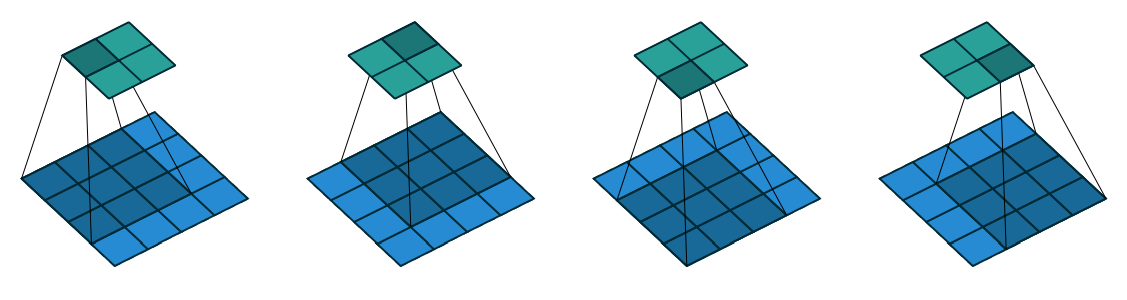
Figure 1.7: No Padding, Unit Strides
Lets define the output size resulting from this setting
Relationship-1: For any \(i\), \(k\), and for \(s=1\) and \(p=0\),
Lets consider zero padding only restricting stride \(s = 1\). The effect of zero padding increases the size of the input from \(i\) to \(i+2p\)
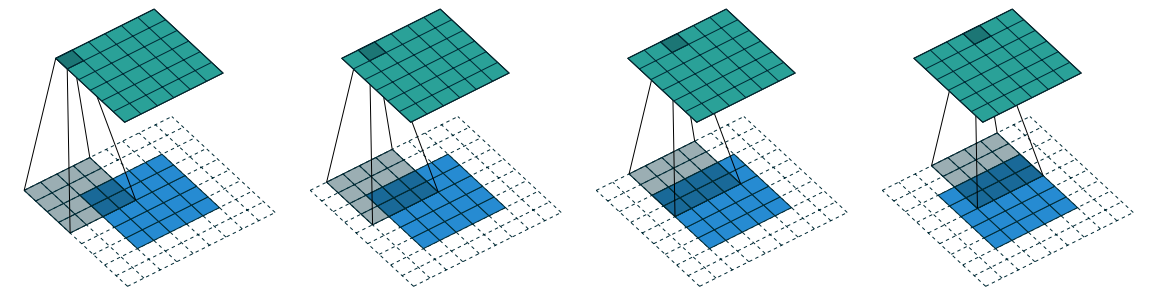
Figure 1.8: Zero Padding, Unit Strides
Relationship-2: For any \(i\), \(k\), \(p\) and for \(s=1\),
Some times we require the output size of convolution to be same as input size (i.e., \(o=i\)). In order for \(o=i\), we use \(p = \lfloor \dfrac{k}{2} \rfloor\)
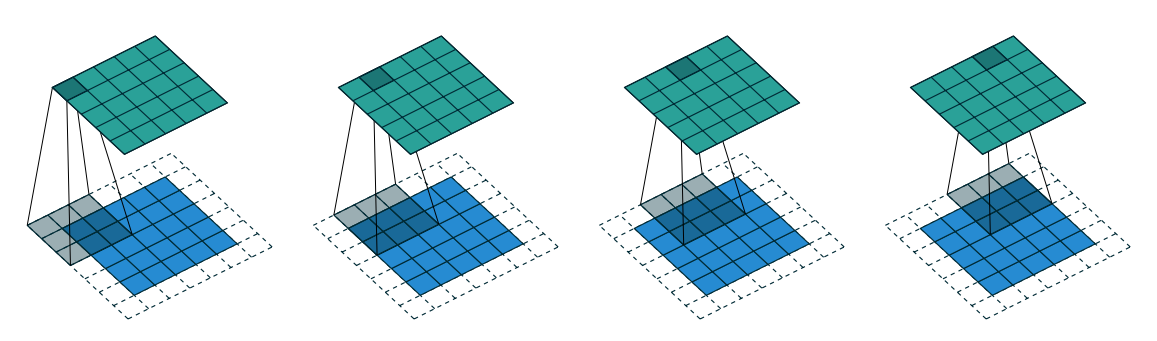
Figure 1.9: Half Padding, Unit Strides
Relationship-3: For any \(i\), and for odd \(k\) (\(k = 2n + 1\), \(n \in N\)), \(s=1\), and \(p = \lfloor \dfrac{k}{2} \rfloor = n\)
Some times we require the output size of convolution to be of larger size than as input. But, convolution always decreases the size of the output if there is no extra padding to the input, so we can do some extra zero padding to the input.
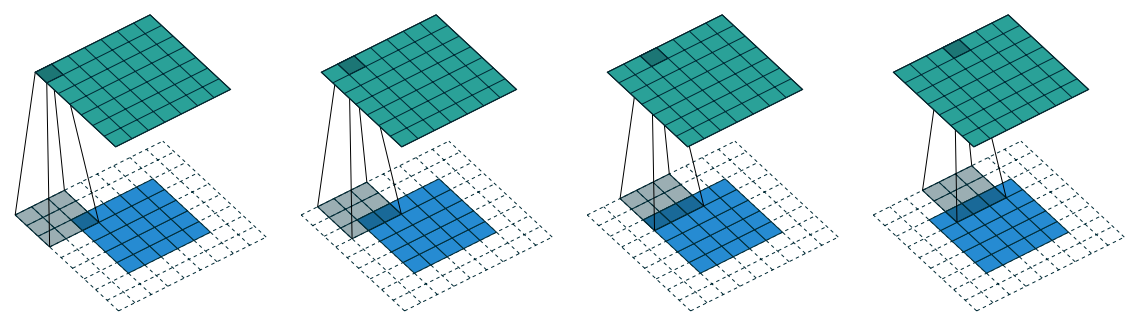
Figure 1.10: Full Padding, Unit Strides
Relationship-4: For any \(i\), and \(k\), \(s=1\), and \(p = k - 1\)
All relationships which we saw till now are unit-strided convolutions. In order to understand the effect of non-unit strides, lets ignore padding for now.
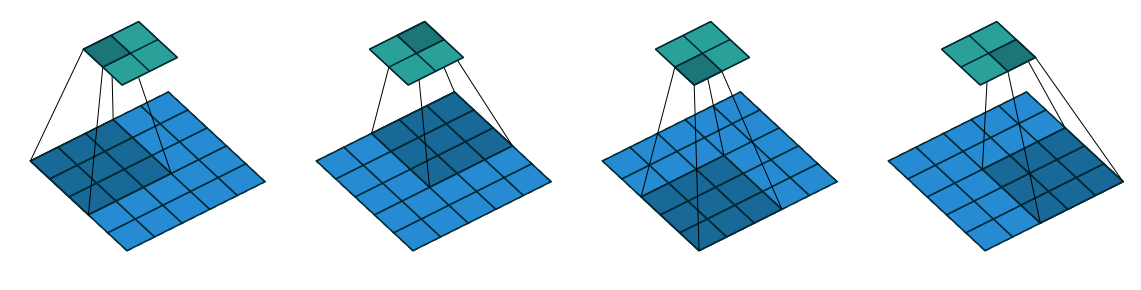
Figure 1.11: No zero padding, non-unit Strides
Relationship-5: For any \(i\), \(k\), \(s\), and for \(p = 0\)
Figure 1.11 provides an example for \(i = 5\), \(k = 3\), \(p = 0\) and \(s = 2\), therefore output size \(o = \lfloor \dfrac{5 - 3}{2} \rfloor + 1 = 2\).
NOTE : The floor function in relationship-5 accounts for the fact that sometimes input size is such that kernel would not be able to reach all the input units.
Figure 1.12 illustrates this
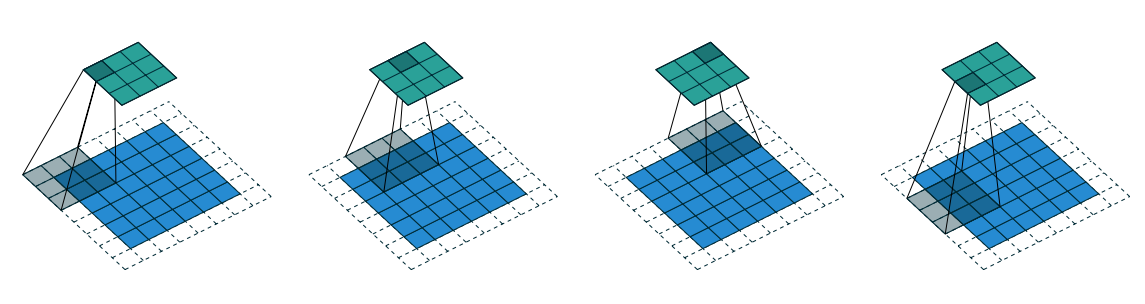
Figure 1.12 Arbitrary padding and Strides
This is the more general case, convolving over a zero padded input using a non-unit strides. We can derive by applying relationship-5 on effective input size of \(i + 2p\)
Relationship-6: For any \(i\), \(k\), \(s\), and \(p\)
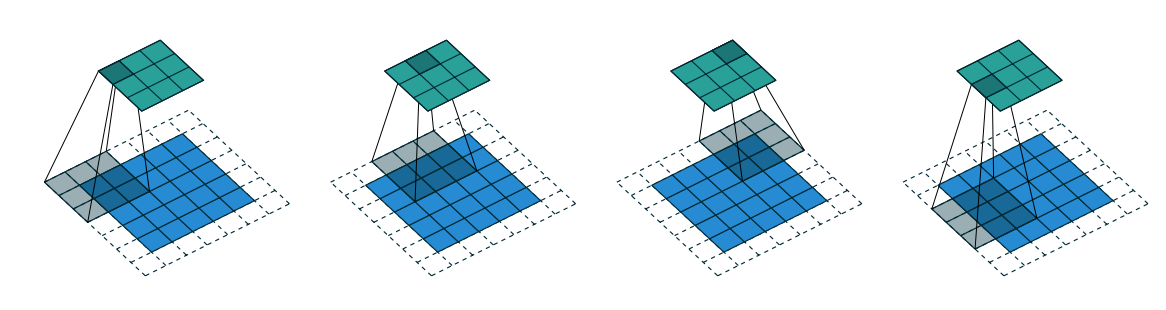
Figure 1.13 Arbitrary padding and Strides
Observe that even though both has different size inputs \(i = 5\) and \(i = 6\), output size after convolution is same \(o = 5\) for both. As discussed before, this is due to the fact that kernel is not able to reach all the input units.
continued in part 2
 Nrupatunga
Nrupatunga