In this post, I will try to give a quick theoretical background to Fully Convolutional neural Network (FCN) and give a little hands on understanding FCN. Basic knowledge of neural network and convolutional network is assumed.
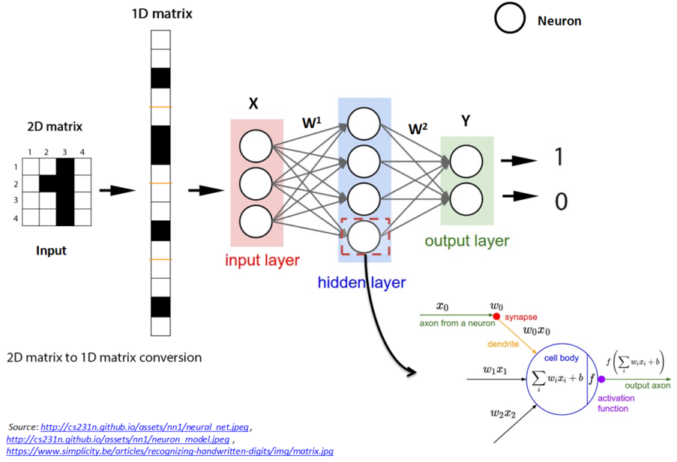
Figure 1: Simple Neural Network
Figure 1.1 shows a simple neural network with input layer, output layer and one hidden layer.
A neural network is composed of layers, each layer consists of number of neurons. Each layer is connected to next layer through some connections which are defined using weights \(W^i\). A neuron is a computational unit, which takes the input \(X\) and outputs \(Y = f(W*X)\), where \(f()\) is a non-linear function like sigmoid, ReLU. Neurons are also called as activation units.
Every neuron in a layer is connected to every other neurons in the next layer. These type of networks are called Fully connected neural networks.
In fully connected neural network, whatever may be the original input structure, it is converted to 1-D matrix / vector before it is fed to the input layer. Outputs will also be 1-D vector. This is illustrated in Figure 1.1.
We learn the weights \(W^i\), by backpropogating the errors through intermediate layers in conjunction with optimization methods such as Gradient Descent and Stochastic Gradient Descent algorithm.
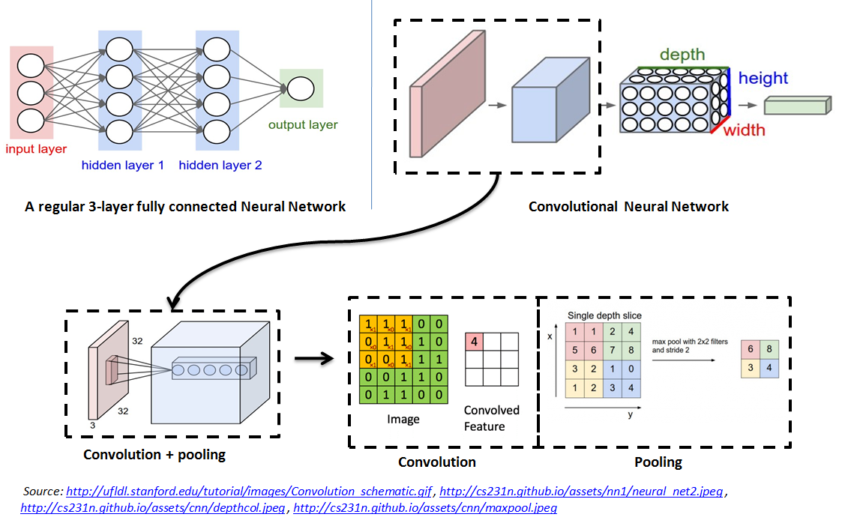
Figure 1.2: Convolutional Neural Network
Figure 1.2 shows the convolutional neural network architecture
Unlike regular neural networks, the layers in CNN have neurons arranged in 3 dimensions: width, height and depth. Here depth refers to the third dimension of the input. For example, in case of color image third dimension is the number of channels
CNN has three types of layers namely Convolution, Pooling and Fully Connected (FC) layers
Every layer of a CNN transforms the 3-D input volume to a 3-D output volume of neuron activations. This is done using operation called as Convolution and Pooling.
Both Convolution and Pooling operations are illustrated in Figure 1.2
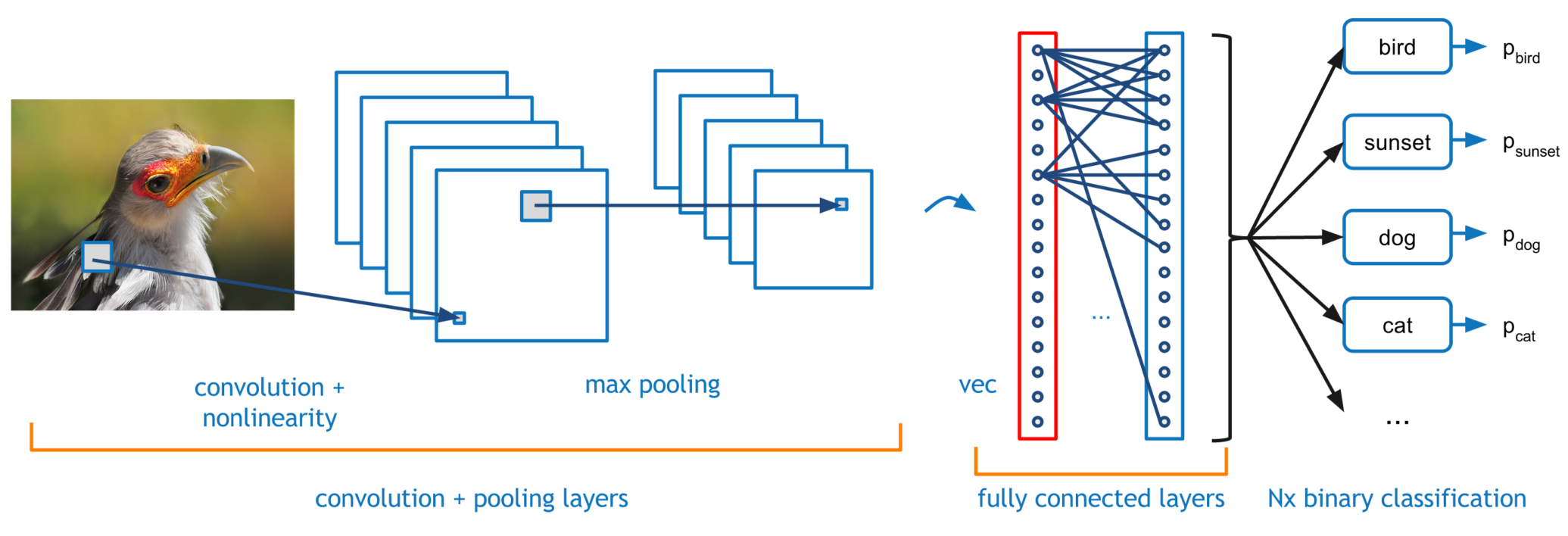
Figure 1.3: Fully connected layers in CNN
Fully Convolutional Neural Network is nothing but CNN, except that final FC layer(s) in CNN are converted to convolution layers, as simple as that. Figure 1.3 illustrates this.
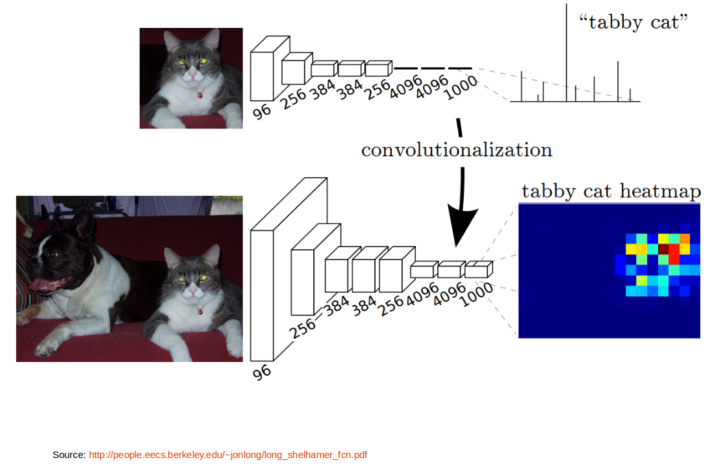
Figure 1.3: Conversion from CNN to FCN
Let us get a quick hands on how to convert a CNN to FCN using Caffe tool. Caffe is a Deep learning framework by the BVLC
 Nrupatunga
Nrupatunga